Afinal, qual o “tamanho” certo para um microsserviço?
Determinar o nível adequado de granularidade (tamanho) ideal para microsserviços em um sistema distribuído é um grande desafio para a arquitetura de software.
 |
Times de desenvolvimento apresentam quedas bruscas de produtividade quando sua capacidade de carga cognitiva suportada é ultrapassada. |
Definição (informal): Carga Cognitiva
Carga cognitiva é a quantidade de informações que uma pessoa consegue manter “em mente” em um determinado momento. Em times, é determinada pela soma das capacidades cognitivas de seus integrantes.
A carga cognitiva pode ser:
- intrínseca, quando tem relação direta com a atividade que está em execução (por exemplo, escrever código para um programador);
- estranha, quando tem relação com o ambiente a atividade é executada (comandos complexos para disparar um processo de build);
- relevante, quando tem relação com aspectos necessários para execução da atividade em alta performance (por exemplo, entendimento do domínio).
Recomenda-se reduzir o esforço para suportar a carga cognitiva treinando as pessoas para lidar com o implícito; automatizar o estranho; liberando tempo para dar ênfase ao relevante.
Nanoservices Antipattern
Um nanoservice é um serviço excessivamente granular no qual a sobrecarga (de comunicação, manutenção, etc) supera sua utilidade.
São métricas objetivas para granularidade em um microsserviço:
- a quantidade de statements em seu código-fonte;
- a quantidade de operações expostas na sua interface púbica.
Ambas métricas são claramente, subjetivas e potencialmente imprecisas, em análises isoladas, entretanto, suficientes nas análises de sistemas inteiros.
O que são microsserviços
 |
Microservices are an approach to distributed systems that promote the use of finely grained services that can be changed, deployed, and released independently.
Sam Newman |
Tradicionalmente, sistemas de software eram desenvolvidos e distribuídos em unidades monolíticas. Ou seja, com todas as funcionalidades em uma única unidade de deploy.
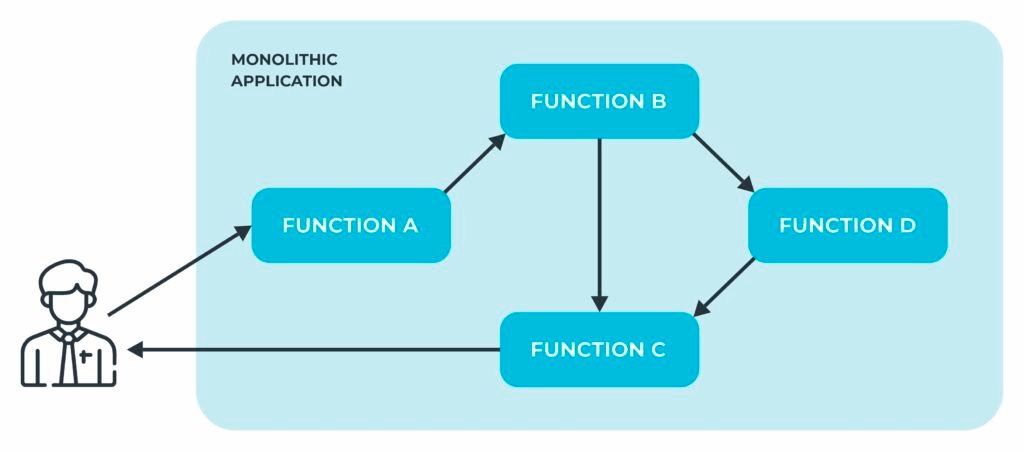
Em sua concepção mais simples, sistemas desenvolvidos a partir de arquiteturas baseadas microsserviços se caracterizam por componentes operando em processos independentes que se comunicam através de APIs bem definidas.
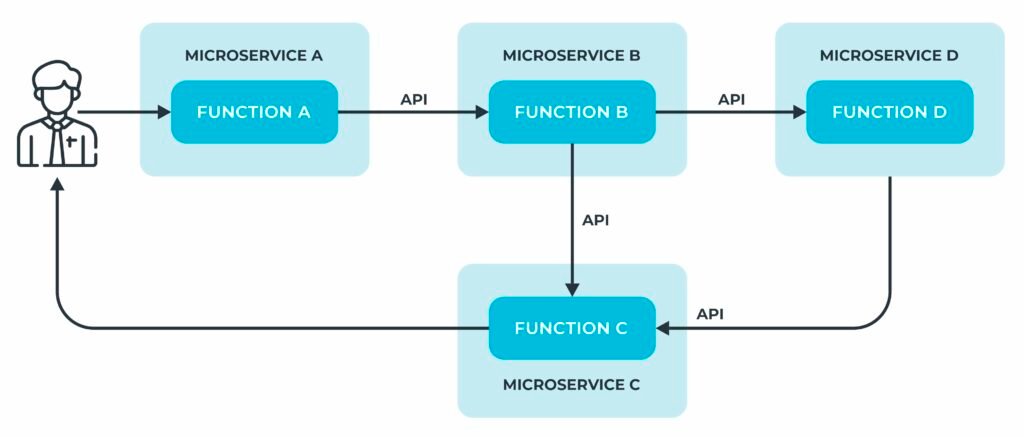
Microsserviços reduzem a granularidade das unidades de deploy, tornando a carga cognitiva associada a cada serviço, em teoria, menor em função do encapsulamento.
Diferença entre 'Deploy' e 'Release'
No deploy ocorre a distribuição de artefatos necessários para o funcionamento de um sistema no ambiente produtivo. Já o release implica na disponibilização de features, direta ou indiretamente, para os usuários do sistema.
A desvinculação de release e deploy autoriza a distribuição de artefatos mais cedo e de forma contínua, permitindo antecipar, inclusive, dificuldades para a operação, mitigando riscos. Quando uma feature está pronta, pode ser facilmente habilitada pela sua feature toggle. Se algo der errado em produção, no lugar de um rollback, bastará desabilitar o toggle para retornar o sistema ao estado anterior, com prejuízos mínimos.
Modularidade antes de granularidade
Single Responsibility Principle (SRP)
O princípio da responsabilidade única é o primeiro dos princípios SOLID para o bom design orientado a objetos.
Segundo o SRP, cada módulo, classe ou função em um programa de computador deve ter responsabilidade sobre uma única parte da funcionalidade desse programa e deve encapsular essa parte. Todos os serviços desse módulo, classe ou função devem estar estreitamente alinhados com essa responsabilidade.
Robert “Uncle Bob” Martin resume SRP como: “Uma classe deve ter apenas uma razão para mudar”. Recentemente, por causa da confusão em torno da palavra “razão”, ele também tem defendido que “SRP é sobre pessoas ou papéis”. Cada “parte” de um sistema deve mudar por demanda de uma pessoa em um papel específico.
Os três tipos distintos de implementações são:
- funcionalidades mais “comuns” necessárias para atender o negócio. Tais funcionalidades suportam diretamente atividades rotineiras e são as mais numerosas em qualquer sistema. Destacam-se, nessas implementações, atendimento direto das demandas de especialistas de domínio (representando o “negócio”).
- suporte a aspectos mais complexos do domínio, incluindo algoritmos, integrações ou estruturas de dados que demandam expertise técnico diferenciado. Geralmente, essas implementações suportam o desenvolvimento das “funcionalidades comuns”.
- facilidades técnicas, geralmente com relação direta com demandas não-funcionais, como a garantia de observabilidade ou resiliência.
Diferença entre 'modularização' e 'granularidade'
Em termos simples, modularização trata da lógica para “quebrar” um sistema complexo em partes, enquanto a granularidade trata do tamanho de cada uma dessas partes.
Geralmente, é recomendável que unidades de implementação determinem a estrutura de times e, daí, naturalmente unidades de deploy (módulos) e de reuso.
 |
Team Topologies: Organizing Business and Technology Teams for Fast Flow Em essência, esse livro destaca a importância de adequar a estrutura de times de uma organização, bem como suas relações, a partir dos três tipos de implementações descritos aqui. |
Quando “quebrar” (aumentar a granularidade)
A decisão de “quebrar” um microsserviço em outros menores, mais granulares, pode ser justificada por diversos aspectos. Em suma, temos: coesão, volatilidade, demandas de escala, demandas de resiliência, segurança e extensibilidade.
O aspecto mais comum e, infelizmente, o mais subjetivo é, sem dúvidas, a coesão, ou seja, o quão relacionadas são as operações expostas publicamente pelo microsserviço que se está analisando. Genericamente, entende-se que um microsserviço precisa atender ao princípio da responsabilidade única (SRP), mas, infelizmente, tal princípio, tão evidente para métodos (e funções) fica um tanto vago quando aplicado em contextos mais amplos (sob a perspectiva da granularidade, pelo menos).
|
Deve-se evitar “quebrar” microsseerviços coesos. |
LCOM
LCOM (Lack of cohesion of methods) é uma métrica genérica adotada para determinar a coesão em classes em códigos implementados no paradigma orientado a objetos. Os valores para esta métrica estão sempre entre 0 e 1. Quanto mais alto o LCOM, maiores são indícios de baixa coesão.
LCOM é definido como 1 - (sum(MF)/M*F).
Onde:
Mé o número de métodos na classe (incluindo estáticos e de instância, construtores, getters/setters e métodos add/remove de eventos).Fé o número de atributos na classe.MFé o número de métodos da classe acessando um determinado atributo.sum(MF)é a soma dosMFpara todos os atributos de uma classe.
Depois da coesão, volatilidade é, provavelmente, o aspecto mais relevante. Sabe-se que códigos modificados com mais frequência são mais propensos a bugs. Por isso, é interessante ponderar “quebrar” um microsserviço em outros menores quando um subconjunto das operações desempenhadas são modificadas mais frequentemente que outras.
Outro aspecto a considerar ao ponderar a “quebra” de uma microsserviço está nas nas variações de tamanho das cargas de trabalho das diversas operações, ou seja, demandas de escala. Subconjuntos das operações de um microsserviço pode possuir demandas de escala muito particulares que ficam mais fáceis de tratar em isolamento.
Analogamente a necessidade de suportar diferentes demandas de escala, subconjuntos de operações podem apresentar, também, demandas diferentes de resiliência (tolerância a falhas), formando “unidades de mitigação” mais fáceis de garantir em “unidades de distribuição” diferentes.
 |
Fundamentos para arquiteturas de sistemas resilientes Manual do Arquiteto de Software |
|
Operações que “quebram” com mais frequência deveriam ficar apartadas daquelas que “quebram” raramente. |
Em tempos onde preocupações com segurança também são crescentes, pode ser útil “dividir” operações conforme as necessidades de segurança, caso estas sejam significativamente distintas.
|
Fundamentos para arquiteturas de sistemas seguros Manual do Arquiteto de Software |
|
Quebrar um sistema em serviços menores, com bases de dados separadas, melhora o controle de acesso a dados potencialmente sensíveis. |
Finalmente, microsserviços deveriam ser “quebrados” quando os diversos “blocos” de operações tiverem diferentes demandas por extensibilidade.
Quando “juntar” (diminuir a granularidade)
A decisão de “juntar” dois ou mais microsserviços, também, pode ser justificada por alguns aspectos. Em suma, temos: consistência por transações, comunicação e reuso de código.
O aspecto mais relevante a se ponderar sobre “juntar” dois ou mais microsserviços é a necessidade deles suportarem juntos transações (sobretudo em bases de dados) como meio para garantir integridade e consistência.
Outro aspecto importante é a comunicação, ou melhor, aquantidade de “conversa” necessária entre dois microsserviços para que eles cumpram suas atribuições. Se um microsserviço consegue suportar atomicamente a maioria inquestionável (70%+) da sua carga de trabalho, então é OK manter sua granularidade. Caso contrário, é razoável promover a “junção” em favor da coesão.
|
“Coesão distribuída” se traduz em de acoplamento, com prejuízos frequentes para o desempenho e para a responsividade. |
 |
Entity Services Antipattern Nesse artigo, Michael Nygard pondera sobre as consequências de desenvolver serviços cujo o propósito é “prover dados” sobre entidades. |
Não se pode ignorar, também, a necessidade de compartilhamento de código. Código “compartilhado” entre dois ou mais microsserviço tem acoplamento aferente maior e, por isso, é mais difícil de manter e evoluir. Além disso, é necessário que se garanta equivalência entre “unidades de reuso” e “unidades de distribuição”.
 |
Java Application Architecture: Modularity Patterns with Examples Using OSGi Este livro é, talvez, a principal referência disponível para interessados em arquitetura de software sob a perspectiva física (modular). Mesmo com exemplos em Java usando OSGi, apresenta padrões e conceitos aplicáveis em qualquer stack tecnológico.
|
|
A necessidade de compartilhamento de código grandes porções de código contendo regras do negócio é um bad smell importante. |
Para pensar…
O hype entorno de arquitetura baseadas em microsserviços tem influenciado exageradamente arquitetos e desenvolvedores em favor da “fragmentação” de sistemas. Entretanto, é importante que se destaque que sistemas fragmentados ingenuamente se convertem, rapidamente, em “pesadelos distribuídos”.


